Hvorfor er en Telugu-tegning bricking Apple-enheter
Apple har hatt en buggy noen måneder. Nå har vi fått en ny, alvorlig feil i tekstgengivelsesfunksjonaliteten i iPhone. Feilen utløses av en enkelt telugu karakter som kan føre til at en iPhone kommer inn i en ubrytelig oppstartsløype bare ved å motta et varsel som inneholder tegnet. La oss dykke inn på hvorfor et enkelt tegn kan forårsake slike store problemer med iOS.
Merk: En løsning for Telugu-feilen er tilgjengelig i den nyeste versjonen av IOS (11.2.6). Hvis Telugu-tegnet har låst opp appen eller enheten din, gjenoppretter du iPhone via iTunes og oppdaterer til den nyeste versjonen av IOS. Hvis iPhone er fast i en oppstartsløyfe, må du kanskje sette den i DFU-tilstanden (Device Firmware Update) for å få iTunes til å gjenkjenne det. Når du er ferdig, gjenoppretter du enheten fra den nyeste sikkerhetskopien din, som du forhåpentligvis opprettet.
Hva er telugu?

Telugu er et språk som er skrevet og skrevet i deler av India, spesielt state of Andhra Pradesh, Telangana, og i byen Yanam. Som mange skriptbaserte språk, for eksempel arabiske og andre brahmiske skript, bruker Telugu noen spesielle funksjoner i Unicode-tegnsettet for å vise tegnene på en dataskjerm.
Mens de fleste latinske bokstaver er representert av et enkelt 8-bits Unicode-kodepunkt for ASCII-kompatibilitet (for eksempel finnes bokstaven A ved Unicode-kodepunktet U+0041, som er representert binært innen 01000001 ), språk skrevet med skript eller ikke- Latinske bokstaver kombinerer vanligvis mer enn ett Unicode-kodepunkt som representerer tegnene sine.
Dette gjelder spesielt for språk, som telugu, som kombinerer språkversjonene av brev i klynger. Til forskjell fra engelsks stilistiske ligaturer er forbindelsen mellom hver telugu-bokstav lingvistisk viktig. For å imøtekomme dette, inkluderer Unicode et komplekst system for å feste tegn, som hver representeres av sitt eget kodepunkt, til hverandre.
Tatt i betraktning det rene antallet Unicode-kodepunkter, kan dette skape nær-uendelig variasjon. Disse punktene kombineres for å gi en lesbar karakter. På denne måten trenger Unicode ikke et Unicode-kodepunkt for bokstavelig talt alle mulige Telugu-ord. I stedet kombinerer Unicode Telugu konsonanter, vokaler og diakritiker ("virama") sammen for å lage ord som vises som en enkelt karakter. Det samme gjelder for andre språk med ortografiske regler for ligaturer, som arabisk.
Hva forårsaker ulykken?

Problemet ser ut til å være relatert til Zero Width Non-Joiner (ZWNJ) ved kodepunkt U+200C . ZWNJ ber om at to tilstøtende tegn gjengis uten deres typiske ligatur. På engelsk holder en ZWNJ tegnene ff fra å bli skrevet ut med sin standardforbindelsesligatur, i stedet skiller hver f. Men når kombinert med et bestemt sett med fire Telugu-kodepunkter (som alle burde kombinere til en enkelt klynge), kan iOS av en eller annen grunn ikke vise resultatet riktig.
Noen har spekulert om at Apples San Francisco-skrift ikke kan vise tegnet, mens andre har sagt at den spesifikke gjengivelsesprosessen Apple bruker, er skylden. Uansett den eksakte årsaken, forsøket på å gjøre karakteren forårsaker en dramatisk krasj av det som gjør det, fra Meldinger og WhatsApp til Springboard. Unicode-koden poeng som utgjør tegnet ("gya" som betyr "kunnskap") er under:
U+0C1Cja (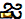 )
)U+0C4Det virama eller diakritisk karakter ( )
)U+0C1Enya (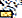 )
)U+200Cnull bredde ikke-joinereU+0C3Eaa (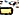 )
)
 )
) )
) )
) )
)Men vi kan ikke engang klandre Zero Width Non-Joiner (ZWNJ) alene. Det er også brukt i den uskyldige familien emojis (????) Uten noe problem. Det ser ut til å være en bestemt kombinasjon av noen spesifikke kodepunkter og ZWNJ. Å legge til fornærmelse mot skade, ser ut til at ZWNJ heller ikke har noen særlig effekt på gjengivelsen på denne telugu-klyngen, eller at den ikke engang skulle være der i utgangspunktet.
Andre Brahmic Script Problemer
Telugu er ikke det eneste språket med dette problemet. Bengali og Devanagari, som bruker Unicode på samme måte for deres Brahmic-skript, har det samme problemet. Manish Goregaokar skriver et fasctinerende og detaljert blogginnlegg som ødelegger det eksakte krasjfallet enda lenger:
Enhver sekvens
i Devanagari, Bengali og Telugu, hvor:1.
consonant2er suffiks-sammenføyning (pstf/pstf)
2.consonant1er ikke et reph-forming letter
3.vowelhar ikke to glyph-komponenter
Konklusjon: Hvorfor var dette ikke fanget av Apple?
For å forstå hvordan denne feilen kom igjennom, må du sette deg i Apples sko. Sikker på at denne tegnkombinasjonen ikke er noe super skjult ord på telugu-språket. Men iPhone inkluderer støtte for dusinvis av språk. Det er bokstavelig talt milliarder potensielle kombinasjoner i Unicode. Med så mye variasjon, vil meningsfull testing av Unicode-feil før en utgivelse gjøre det mulig å gjøre regelmessige programvareoppdateringer i utgangspunktet umulige.
Feilen bør imidlertid ikke ha forårsaket så mye skade. Telefoner skal ikke bli muret basert på innholdet i en tekstmelding. Mens etterfølgen er sikkert 20/20, virker det som å gjøre karakteren som et spørsmålstegn boks ( ) ville vært bedre enn å krasje Springboard.